




Before testing memory, WRBench checks whether the generated video actually follows the requested look-away-and-return motion.
control before memory
Benchmarking whether video world models remember off-screen change
WRBench makes the model look away and come back: the scene is fixed, the event happens off-screen, and the returned view must show what changed.
If a cat jumps onto a bed while hidden, it should still be on the bed when the camera returns.
The gap
Start in a bedroom with a cat on the floor. Turn the camera away. The prompt says the cat jumps onto the bed. Turn back. A real world keeps unfolding while it is not being watched. Evaluated video generators often do something weaker: the cat may drift, duplicate, vanish, or reset. A world model should preserve what happened, not just draw a plausible returned frame.
Before testing memory, WRBench checks whether the generated video actually follows the requested look-away-and-return motion.
The visible frames must be coherent enough to judge the scene and the action before the hidden change is tested.
When the target comes back into view, WRBench checks whether its location and state match the event that happened off-screen.
The same teaser scene and camera path are shown across three models. The expected outcome is simple: after the camera returns, the cat should be on the bed.
The cat reaches the bed, and the returned view still supports that outcome.
The cat is carried along with the camera instead of completing a clean jump.
The camera returns, but the expected cat-on-bed state is not established.
Why this case: it is the same teaser and overview scene, so the expected endpoint is unambiguous. The montage anchors the task; the three clips above show whether a model reaches that endpoint, drags the target, or fails to re-establish the returned state.
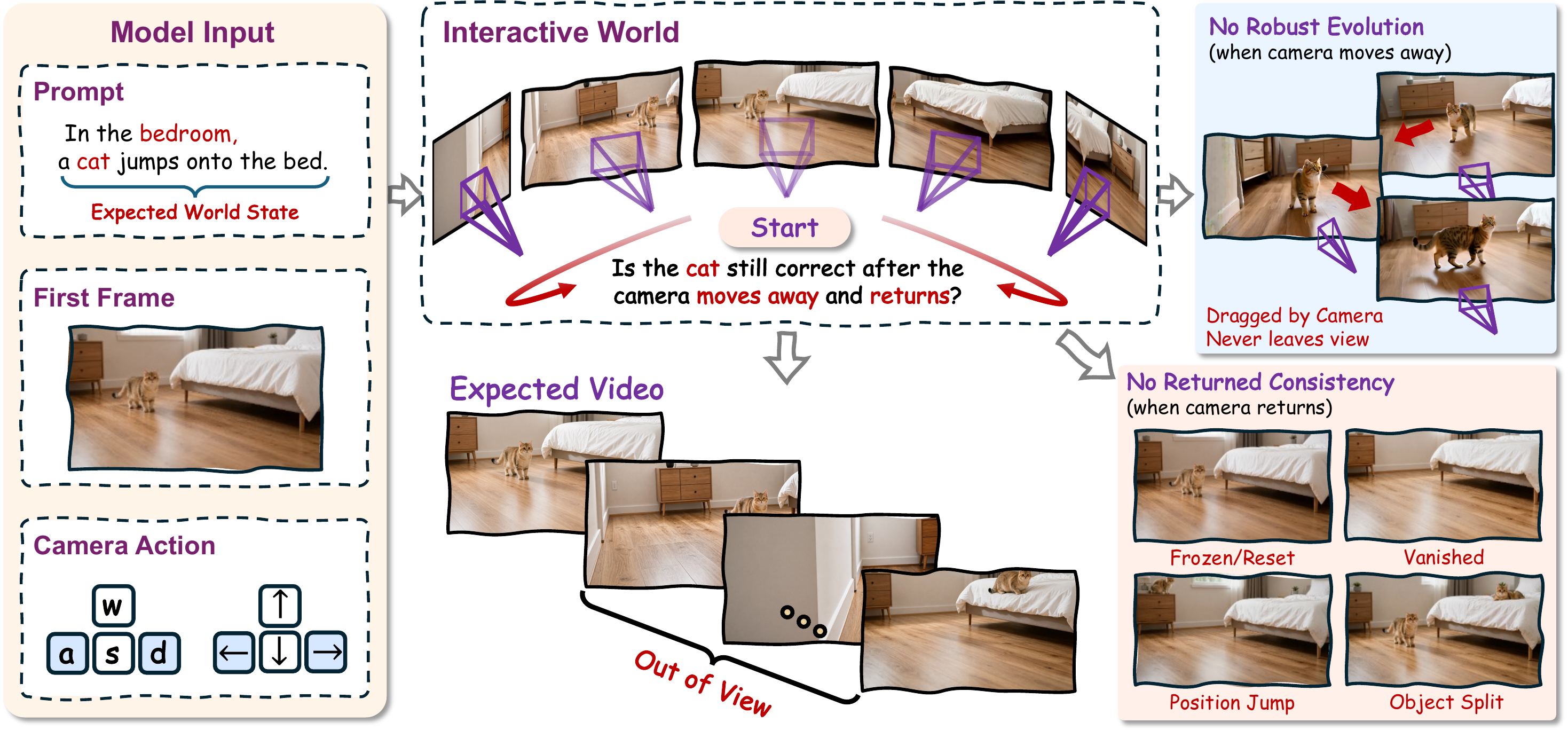
Frame montage: the camera looks away during the jump, then returns to check whether the off-screen outcome was kept.
Findings
From 23 models and 9,600 videos, the pattern is consistent: models can make clean videos, follow a camera, and bring objects back into view, yet still lose what changed while hidden.
Six headline findings, stated as mechanisms rather than a single leaderboard rank.
Positioning
Table 1 from the paper. Prior benchmarks cover important parts of video and world-model evaluation. WRBench adds a specific stress test: change the viewpoint, hide the target, return, and ask whether the hidden event outcome stayed true.
Diagnostic profile
WRBench does not collapse everything into one score. The table separates whether the camera was followed, whether the visible frames are readable, whether the target returns, and whether the returned state is correct. Click any header to sort.
Visible consistency — often strong; it does not guarantee a correct return.
Re-observation — whether the return can be judged, not whether it is correct.
Re-observation consistency — the outcome WRBench is designed to measure (2,073 judgeable clips).
† Reobs. spatial and Reobs. state are conditional means over the judgeable re-observation subset. Avg. is the paper's mean of Cam Align., Integ., Vis. spatial/state, and Reobs. spatial/state, excluding re-observation support. Italic re-observation scores mark low re-observation support (fewer than 10 judgeable clips or support below 10%). Cam Prec. is not applicable to prompt-only API rows.
Diagnosis
The diagnosis is not that one model loses. The hard part is specific: a model may show the target again but still fail to keep the off-screen change. In-place changes such as folding, tipping, or sitting are especially fragile.
Visible quality and re-observation consistency barely move together — score the return, not the frame.
In-place state change is the universal hard case; relocation is easier to preserve.
Scale, architecture, and training mostly add re-observation support — not re-observation consistency.
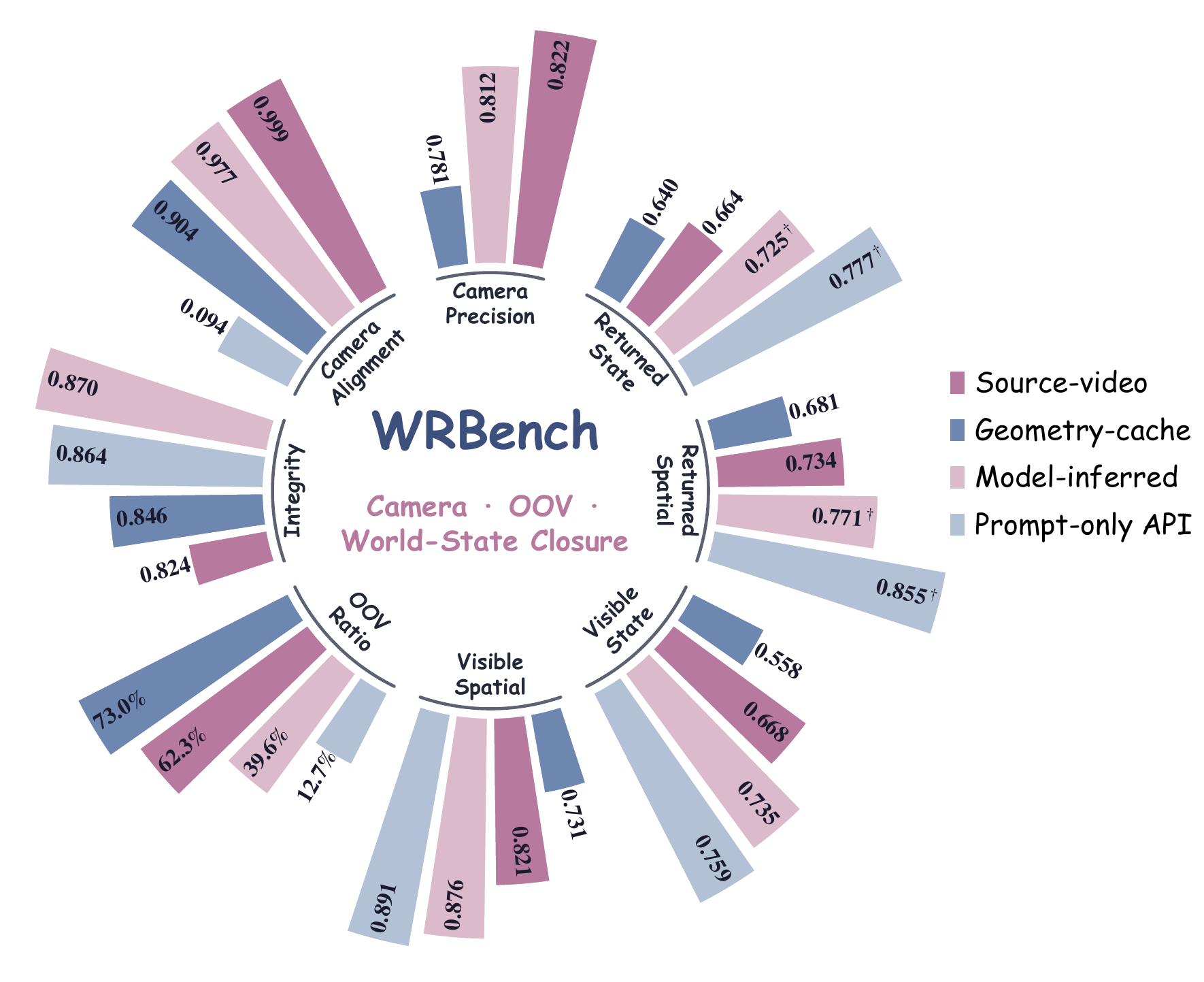
Figure 4. Best score each viewpoint condition type reaches on every diagnostic dimension; frontiers expand on visible/support axes, not re-observation consistency.
How to read this: each spoke is one diagnostic dimension; the colored outline is the best score reached by a viewpoint condition type. A bigger outline = better on that axis.
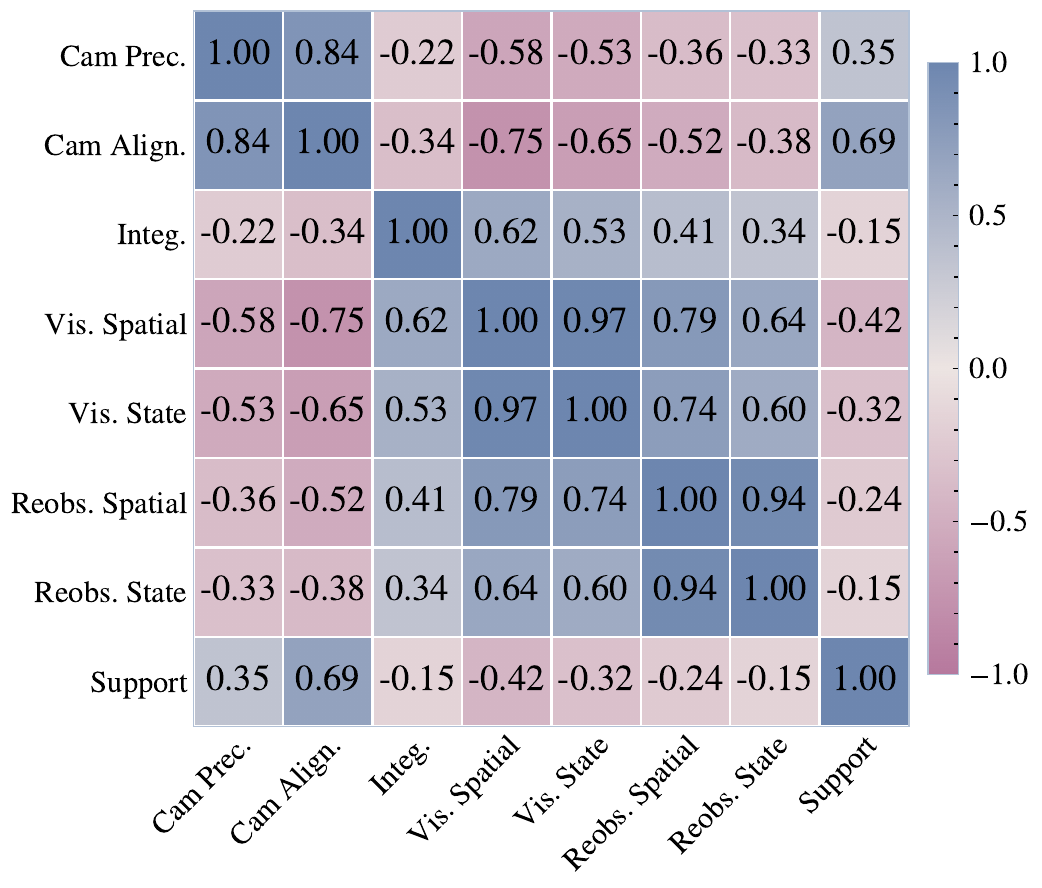
Figure 5. Model-level correlations among the diagnostic metrics (23 rows), with visible and re-observation consistency forming separate blocks.
How to read this: darker = stronger correlation. If two metrics rose together, image quality would predict a correct return. They don’t.
How to read this: each group of bars is a camera condition. Watch how re-observation support grows while re-observation consistency bars stay flat.
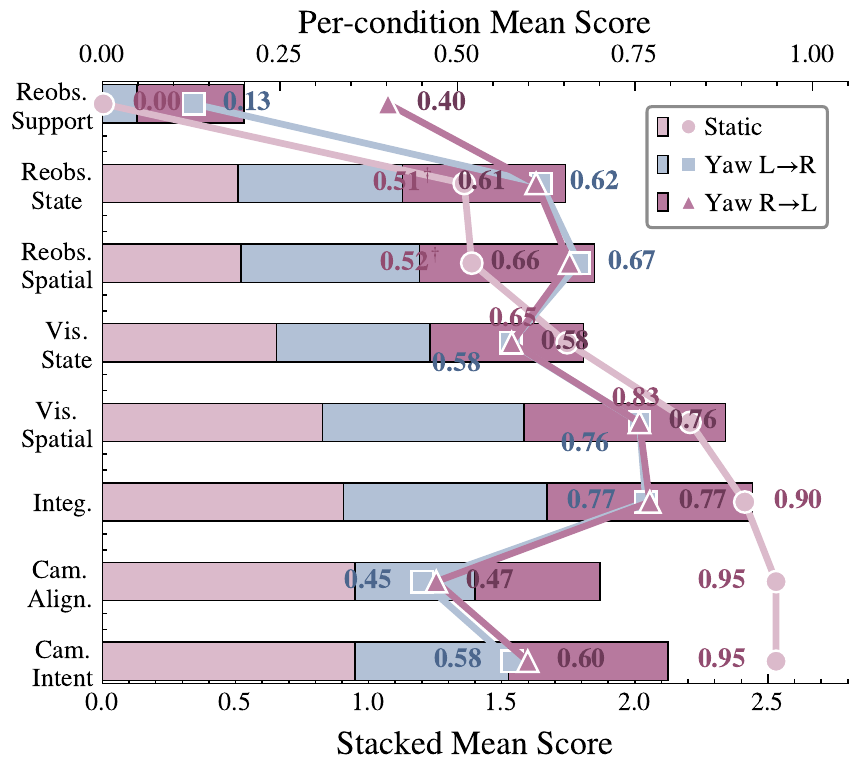
Figure 6. Static hold vs. horizontal camera pan: re-observation support moves, re-observation consistency does not.
How to read this: each event is split into two switches — did the object move, and did its state change. The boxes compare flipping one at a time.
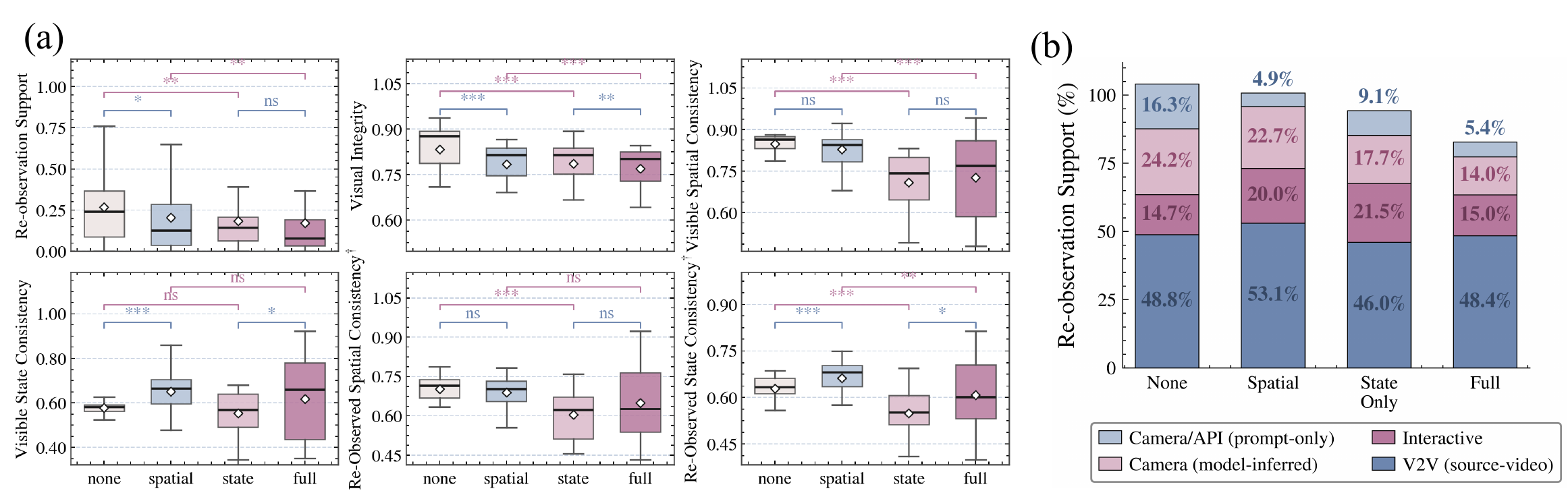
Figure 7. Metrics under a 2×2 event design; stars mark paired Wilcoxon significance.
How to read this: the left panel asks which model inputs make the return visible. The Wan-family panels then vary scale, architecture, and training signal to ask whether any of them preserve the hidden outcome.
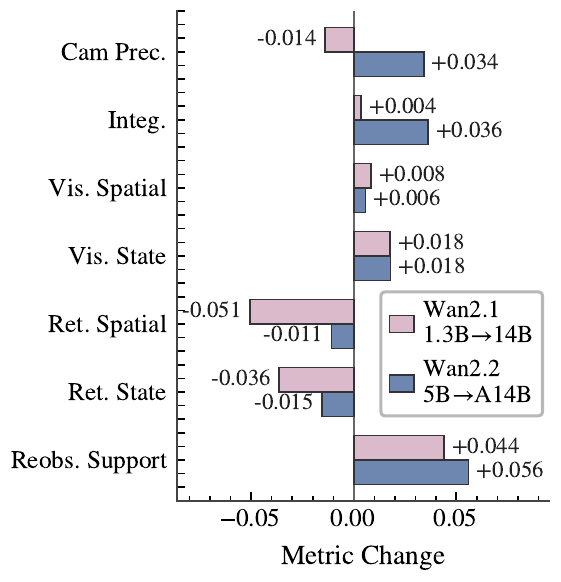
Figure 8A · Wan scale / version diagnostics
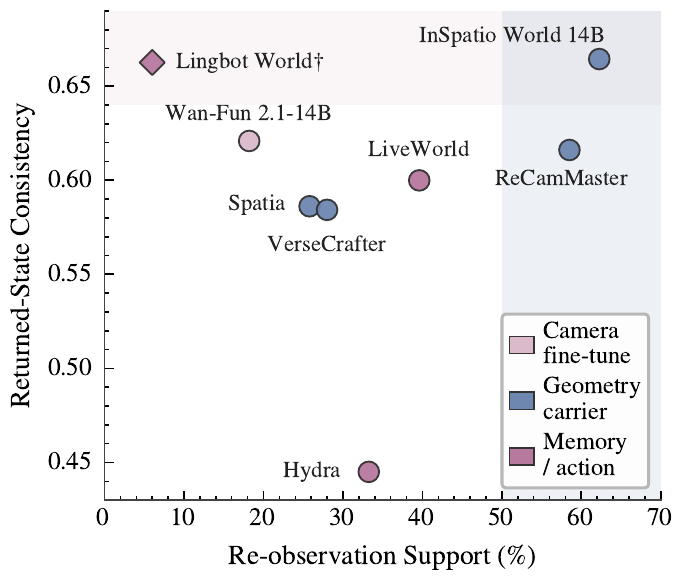
Figure 8B · Wan architecture diagnostics
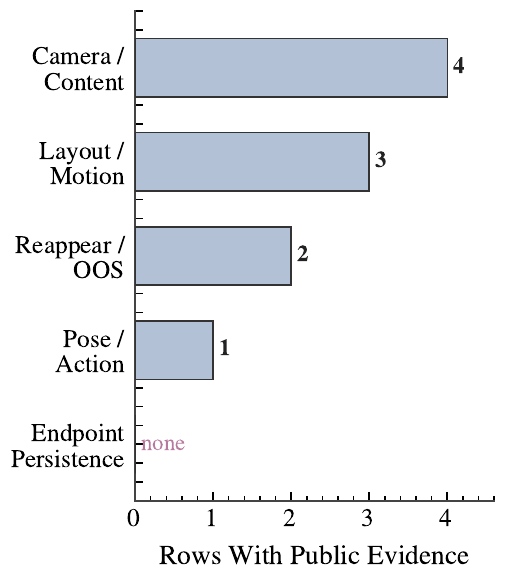
Figure 8C · Wan training-signal diagnostics
Cases
These clips match appendix montages in the paper. They show three recurring patterns: camera direction controls whether a return can be judged, returning into view does not guarantee a correct state, and in-place changes remain hard.
Forensics
Appendix montages show how a video can look readable, move the camera, and show visible action, yet still return to the wrong location or state.
Method
WRBench fixes the scene, the event, and the camera path, then keeps enough generation detail to compare very different models fairly. The six checks separate visible consistency, re-finding the target, and preserving the returned state.
25 scene families × 4 event tiers × 3 camera conditions. Events span fold, jump, knock, place, sit, and tip — from spatial relocation to in-place state change.
Every generated clip is paired with the exact input condition the model received, so prompt-only, image-conditioned, and video-conditioned systems are compared on the evidence they were actually given.
2,547 deduplicated annotator verdicts over 1,156 comparison pairs calibrate automatic evaluators dimension by dimension.
Prompt-only, model-inferred camera, geometry cache, and source video routes carry different amounts of already-seen scene evidence.
Each test starts from the same scene and event, then changes the camera path so the target either stays visible, becomes hidden, or returns. The prompt does not reveal the final answer; the generated video must carry the off-screen outcome.
For every model, WRBench keeps the model input, the requested camera path, the generated video, and the scoring evidence together.
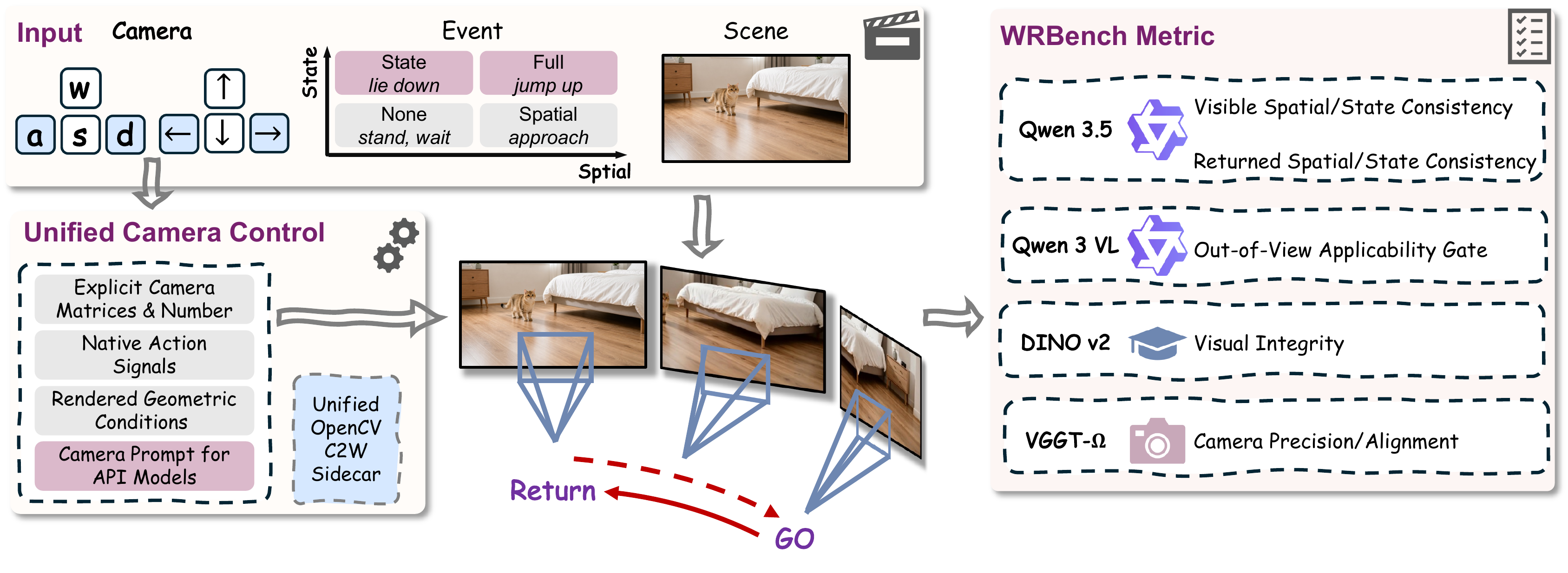
WRBench pipeline: camera following, visible quality, visible consistency, re-observation support, and re-observation consistency are measured separately.
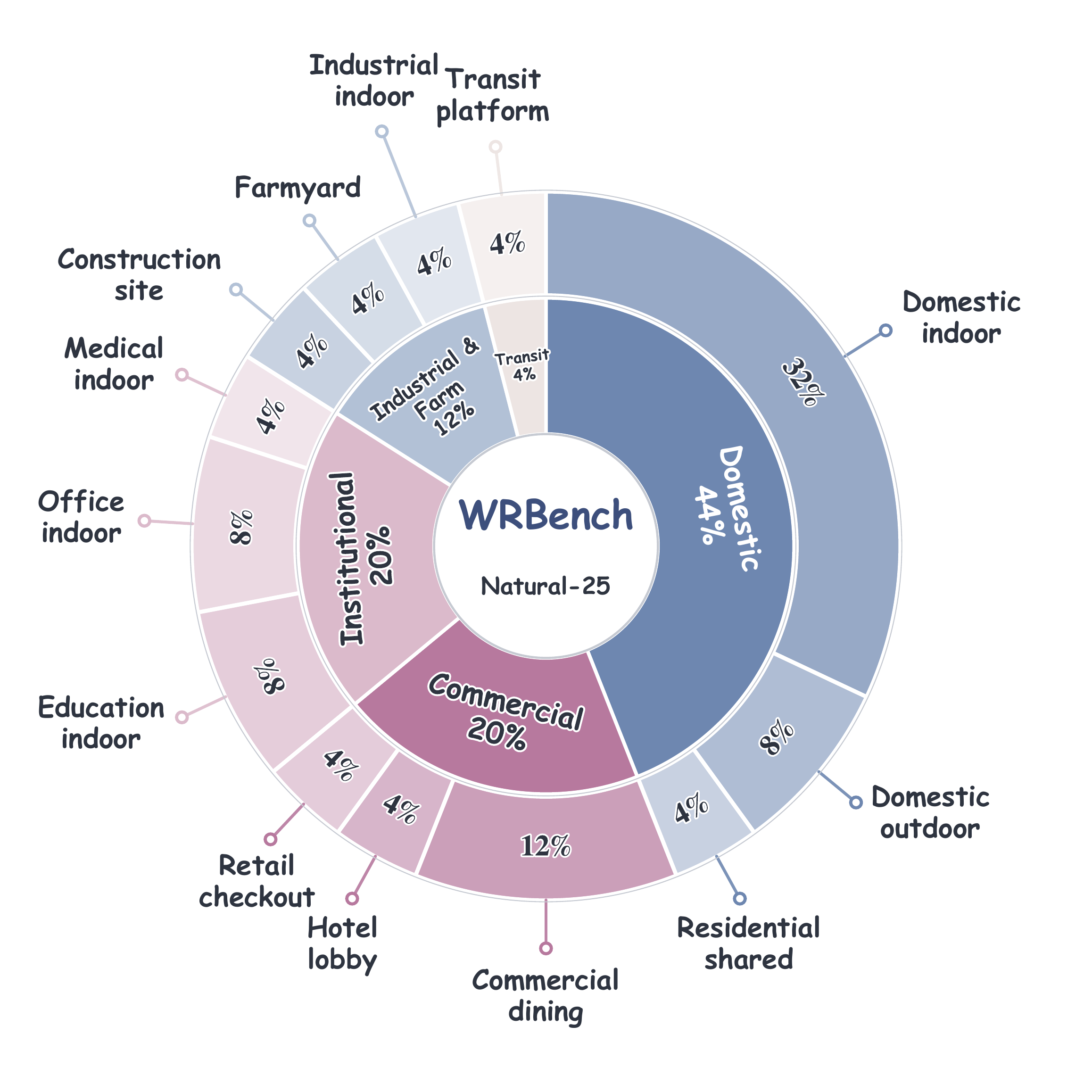
Natural-25: scene families × spatial/state event tiers × camera conditions.
Dimensions
Human
2,547 deduplicated annotator verdicts over 1,156 released comparison pairs validate each WRBench check separately — not one collapsed preference score. Agreement uses prevalence-robust AC1; rank ρ is Spearman alignment between the automatic margin and the ordered human label.
Visual integrity uses a separate 190-pair holdout. Rev. counts opposite-direction threshold decisions; thresholds are fixed before reporting. Disagreement appears mainly as ties around small differences, not systematic reversal.
Cite
@misc{lu2026currentworldmodels,
title={Current World Models Lack a Persistent State Core},
author={Jinpeng Lu and Dexu Zhu and Haoyuan Shi and Linghan Cai and Guo Tang and Yinda Chen and Jie Cao and Duyu Tang and Yi Zhang and Yong Dai and Xiaozhu Ju},
year={2026},
eprint={2606.20545},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2606.20545}
}